
2734-python+selenium爬虫按关键词搜索实现自动化抓取淘宝商品写入mongodb数据库
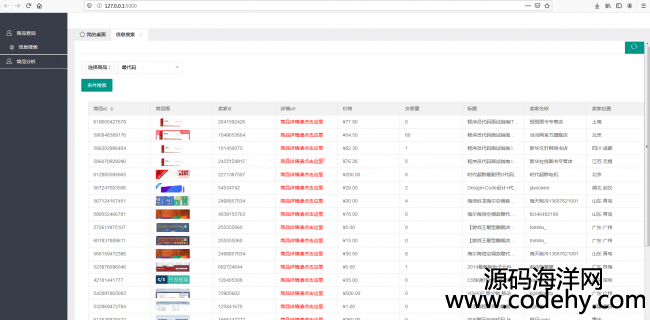
使用selenium、webdriver爬取淘宝的图片、商品、价格等信息。在命令行界面输入爬取的参数,把参数信息记录到txt文件中,运行爬虫程序后,先使用手机扫码登陆,然后pc端网页会自动翻淘宝的网页,知道翻到淘宝的最后一页,就会停止对商品的爬取
web端功能:
1.下拉框选择商品搜索
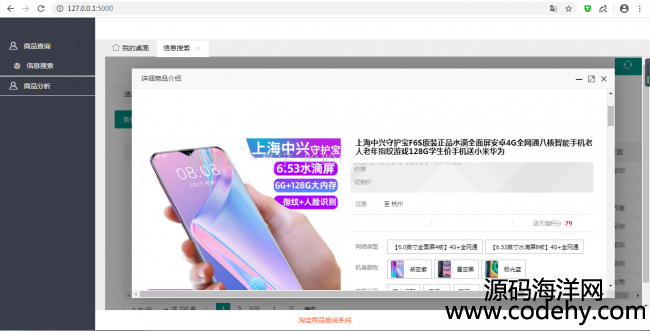
2.点击图片放大
3.点击详情,查看商品详情
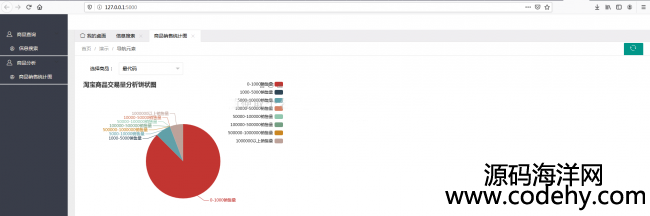
4.用饼图查看交易量占比
运行:
1.新建命令行记录文件。命令行记录文件是记录爬虫时,你输入的商品名字和数据库名字(具体位置是E:\a\cmd.txt) 2.pip安装selenium,然后查看你的chrome版本,根据你的版本安装webdriver.exe。具体教程: 3.启动爬虫(商品名字是要在淘宝搜索的商品,数据库名字是爬取的商品要存在哪个数据库里面,数据库名字最好是拼音或者英文) python crawl_taobao.py -k 商品名字 -d 数据库名字 4.启动web: python runserver.py
运行环境
python+pycharm
项目技术
python+selenium+mongodb+layui
数据库文件
mongodb
依赖包文件
>pip install pyquery
>pip install pymongo

本源码地址:http://www.codehy.com/vip/python/2020/0626/21300.html