
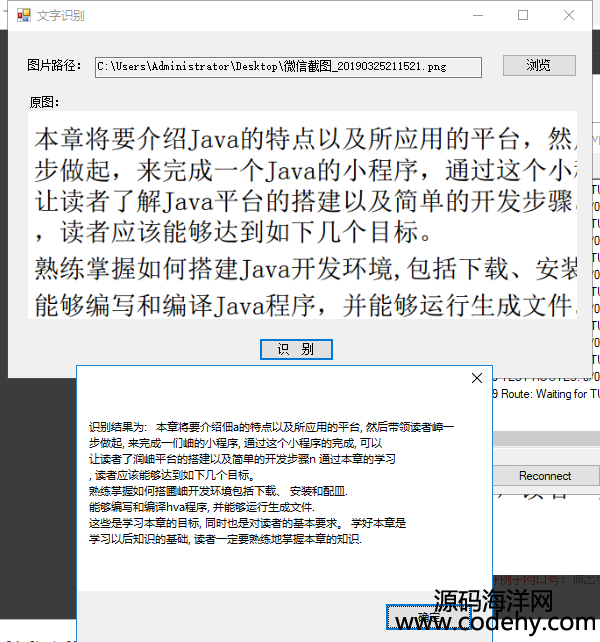
1141-C# Winform识别图片文字源码 tesseract OCR
关于软件的使用:在win7及一下的电脑上运行时需要安装.net framework4.0,另外该程序对只包含文本,且文本清晰的图片识别率较高,另外随着文字的增多识别的成功率会下降。
该软件采用的是Tesseract及其配套的训练库来实现图片中的文字识别(包括中文)。
如果读者要自己创建同样的识别程序需要注意的地方有以下几点:
1、 需要的文件有:Tesseract.dll和chi_sim.traineddata。这两个文件在该项目目录下均可以找到。
2、 项目目标处理器必须设置为x86,不然运行不通过
3、 使用时,将Tesseract.dll添加到项目引用中。如果准备使用.net4.0框架主要修改app.config与本文件中的app.config一致。如果不想修改app.config,请将项目.net框架降低3.5版本,否则编译时出错。
4、 主要的识别过程如下:
Bitmap bmp = new Bitmap(textBox_Path.Text);
TesseractProcessor process = new TesseractProcessor();
process.SetPageSegMode(ePageSegMode.PSM_SINGLE_LINE);
process.Init(System.Environment.CurrentDirectory+"\\","chi_sim", (int)eOcrEngineMode.OEM_DEFAULT);
string result = process.Recognize(bmp);
MessageBox.Show("识别结果为:"+result);
其中process.Init函数的第一个参数为chi_sim.traineddata的路径,本项目中为软件运行目录下(记着把文件放在指定目录下,不然运行会出错的),记得最后还有反斜杠。第二个参数为训练库名不带扩展名的。第三个参数不用管,原封抄下就可以了。
5、 另外注意文件chi_sim.traineddata是训练库文件,如果觉得识别率不高可以自己再网上找Tesseract的训练库,替换该文件。
本源码地址:http://www.codehy.com/vip/net/2019/0801/19738.html








