业务背景
大家在平时的生活或工作种多少都会遇到类似下面的情况吧
非技术人员:
我身边有同学在一家装修设计公司上班,她每天的工作就是去其他各大装修平台,去“借鉴”别人家设计师的创意,找到合适的图片,就会一张张点击图片另存到自己电脑中。
其实这些工作都是重复性且毫无技术含量,完全可以用工具自动化实现。
技术人员:
比如我喜欢看一些技术帖子(微信公总号,技术博客等),有时候会觉得文章中的一些技术原理、架构图片非常直观,为了方便下次巩固这些技术,我一般都会把图片保存下来。
如果图片不多的话,一般有如下方法
1 点击图片另存为 (原图像素还不错)
2 用手机拍照(像素不好)
如果要下载保存的图片过多,通过以上两种方式去抓取图片,有两个弊端
1 效率低下
2 重复工作,浪费不必要的时间
作为一位懒惰的码农,怎么可以把时间浪费在不需要脑力的事情上呢? 为了减少重复性的工作,便有了这篇文章,我这里写的并不是很深入,只是提供一个思路,实现简单从网页中抓取所有图片并重命名保存到电脑中;希望对大家有所帮助。
开发环境
- jdk1.6&以上
- Eclipse或Intellij idea
- Maven
编码
package com.xyq.maventest.util; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.URL; import java.net.URLConnection; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.commons.lang.StringUtils; import org.apache.http.HttpEntity; import org.apache.http.ParseException; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /**** * * @ClassName: DownloadImageUtil * @Description: 此类主要作用从一个网址上爬图片,然后重命名保存到本地路径中 * @author youqiang.xiong * @date 2018年2月26日 下午12:09:29 * */ public class DownloadImageUtil { /*** * 请求的网址url常量 */ public static final String REQUEST_URL = "https://www.cnblogs.com/EasonJim/p/6919369.html"; /**** * 图片保存路径 */ public static final String IMAGE_SAVE_PATH = "C:\\Users\\youqiang.xiong\\Desktop\\image\\test"; /*** * 获取img标签正则表达式 */ public static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>"; /**** * 获取src路径的正则 */ public static final String IMGSRC_REG = "(http|https):\"?(.*?)(\"|>|\\s+)"; public static String[] IMAGE_TYPE_SUFFIX = new String[]{"=png","=jpg","=jpeg",".png",".jpg","jpeg"}; /**** * 生成图片的名称默认从1开始递增 */ public static Integer imageIndex = 1; public static void main(String[] args) { String htmlContent = parseContext(REQUEST_URL); List<String> imageUrlList = getImageSrc(htmlContent); for(String imageUrl:imageUrlList){ try { download(imageUrl, IMAGE_SAVE_PATH); } catch (Exception e) { System.out.println(e.getMessage()); } } System.out.println("从【"+REQUEST_URL+"】网站,共抓取【"+(imageIndex-1)+"】张图片。"); } /*** * 解析图片url路径,保存到对应目录下 * @param oldUrl 图片链接url * @param savePath 图片报错路径 * @throws Exception */ public static void download(String oldUrl,String savePath) throws Exception { String imageType = ""; boolean flag = false; for(String suffix:IMAGE_TYPE_SUFFIX){ if(oldUrl.lastIndexOf(suffix) > -1 || oldUrl.lastIndexOf(suffix.toUpperCase()) > -1){ flag = true; imageType = suffix.replace("=", "."); break; } } if(flag){ String filename = String.valueOf(imageIndex) + imageType; download(oldUrl, filename, savePath); imageIndex ++ ; } } /***** * 根据图片url路径,下载到对应目录下 * @param urlString 图片url路径 * @param filename 文件名称 * @param savePath 文件报错路径 * @throws Exception */ public static void download(String urlString, String filename, String savePath) throws Exception { if(StringUtils.isEmpty(urlString) || StringUtils.isEmpty(filename) || StringUtils.isEmpty(savePath)){ throw new IllegalArgumentException("方法入参不能为空!"); } File dir = new File(savePath); if(!dir.exists() && dir.isDirectory()){ dir.mkdirs(); } URL url = new URL(urlString); URLConnection con = url.openConnection(); con.setConnectTimeout(5 * 1000); InputStream is = con.getInputStream(); byte[] bs = new byte[1024]; int len; File sf = new File(savePath); if (!sf.exists()) { sf.mkdirs(); } OutputStream os = new FileOutputStream(sf.getPath() + "/" + filename); while ((len = is.read(bs)) != -1) { os.write(bs, 0, len); } os.close(); is.close(); } /**** * 通过httpclient,读取url中的响应内容并返回 * @param url 请求的url路径 * @return */ public static String parseContext(String url) { if(StringUtils.isEmpty(url)){ throw new IllegalArgumentException("访问地址url不能为空"); } String html = null; CloseableHttpClient httpclient = HttpClients.createDefault(); try { HttpGet httpGet = new HttpGet(url); CloseableHttpResponse response = httpclient.execute(httpGet); try { HttpEntity entity = response.getEntity(); if (entity != null) { html = EntityUtils.toString(entity); } } finally { response.close(); } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { httpclient.close(); } catch (IOException e) { e.printStackTrace(); } } return html; } /*** * 获取ImageUrl地址 * * @param htmlContext * @return */ private static List<String> getImageUrl(String htmlContext) { if(StringUtils.isEmpty(htmlContext)){ throw new IllegalArgumentException("html请求内容不能为空."); } List<String> listImgUrl = new ArrayList<String>(); Matcher matcher = Pattern.compile(IMGURL_REG).matcher(htmlContext); while (matcher.find()) { listImgUrl.add(matcher.group().replaceAll("'", "")); } return listImgUrl; } /*** * 获取ImageSrc地址 * * @param htmlContext * @return */ public static List<String> getImageSrc(String htmlContext) { if(StringUtils.isEmpty(htmlContext)){ throw new IllegalArgumentException("html请求内容不能为空."); } List<String> listImageUrl = getImageUrl(htmlContext); List<String> listImgSrc = new ArrayList<String>(); for (String imageContext : listImageUrl) { Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(imageContext); while (matcher.find()) { listImgSrc.add(matcher.group().substring(0, matcher.group().length() - 1)); } } return listImgSrc; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
说明:需要引入httpclient和commons-lang两个jar包
我的项目是通过maven管理,所以只需要在pom.xml中添加以下配置即可
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.4</version> </dependency> <dependency> <groupId>commons-lang</groupId> <artifactId>commons-lang</artifactId> <version>2.6</version> </dependency>
测试效果
1、修改常量
修改RQQUEST_URL 和IMAGE_SAVE_PATH 两个常量值改成你想抓取的网址url和保存图片的路径即可
/*** * 请求的网址url常量 */ public static final String RQQUEST_URL = "https://www.cnblogs.com/EasonJim/p/6919369.html"; /**** * 图片保存路径 */ public static final String IMAGE_SAVE_PATH = "C:\\Users\\youqiang.xiong\\Desktop\\image\\test";
2、运行main方法
3、等待不久,Console控制台会输出一段信息
从【https://www.cnblogs.com/EasonJim/p/6919369.html】网站,共抓取【7】张图片。

4、打开C:\Users\youqiang.xiong\Desktop\image\test 目录查看图片是否成功生成
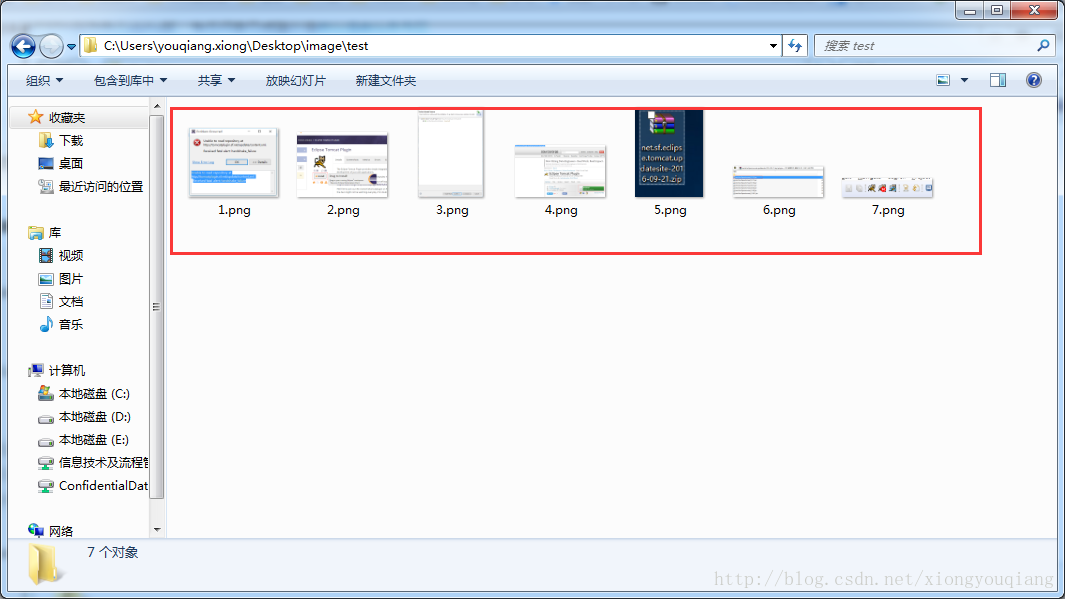
对比https://www.cnblogs.com/EasonJim/p/6919369.html 网址上的图片跟test目录中的发现一模一样,这样就大功告成了。
TODO
以上功能还有一些需要完善和优化的地方,由于时间有限这里还没有太多时间去研究,后续会进一步补充。
1 加入多线程,同时抓取多个网站的图片
2 利用Java swing技术开发图形界面,供普通用户使用